
023-68661681
 返回
返回顶部
iText 7 Core可以被Java或.NET(C#)对PDF文档进行编程。
iText是一个通用的、可编程的和企业级的PDF解决方案,允许你将其功能嵌入到你自己的软件中,以实现数字化转型。
iText 7 Core以开放源码(AGPL)以及商业许可的形式提供。
虽然是开源但是也不代表完全免费,详情可搜索“AGPL协议”。
总体而言对于PDF转office文档等操作是比较全的了,当然PDF转入转出的库也有不少,比如说Aspose和Spire.Office等。

当我们拿到了一份超级大的PDF产品手册时,按照整体内容交付业务貌似体验不佳,那么我们需要对PDF做按页切割,IText的DEMO板块为此提供了完整方案。
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfReader;
import com.itextpdf.kernel.pdf.PdfWriter;
import com.itextpdf.kernel.utils.PageRange;
import com.itextpdf.kernel.utils.PdfSplitter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.IOException;
public class PDFSplitter {
private static final String ORIG = "/uploads/split.pdf";
private static final String OUTPUT_FOLDER = "/myfiles/";
public static void main(String args[]) throws IOException {
final int maxPageCount = 2; // create a new PDF per 2 pages from the original file
PdfDocument pdfDocument = new PdfDocument(new PdfReader(new File(ORIG)));
PdfSplitter pdfSplitter = new PdfSplitter(pdfDocument) {
int partNumber = 1;
@Override
protected PdfWriter getNextPdfWriter(PageRange documentPageRange) {
try {
return new PdfWriter(OUTPUT_FOLDER + "splitDocument_" + partNumber++ + ".pdf");
} catch (final FileNotFoundException ignored) {
throw new RuntimeException();
}
}
};
pdfSplitter.splitByPageCount(maxPageCount, (pdfDoc, pageRange) -> pdfDoc.close());
pdfDocument.close();
}
}虽然IText没有考虑到中国人的阅读习惯(都是英文),但是对于开发者而言已经是很体贴了:
PDF分页切割、合并、内容旋转、分页删除、页面保护、密码消除、图片转换、HTML转PDF等常规操作文档支持很到位。
同时,IText提供了一个框架,根据您在模板中定义的选择规则,智能地识别PDF文档中的数据。这与基于人工智能的替代方案相比具有显著的优势,后者需要大量的培训来识别文档:
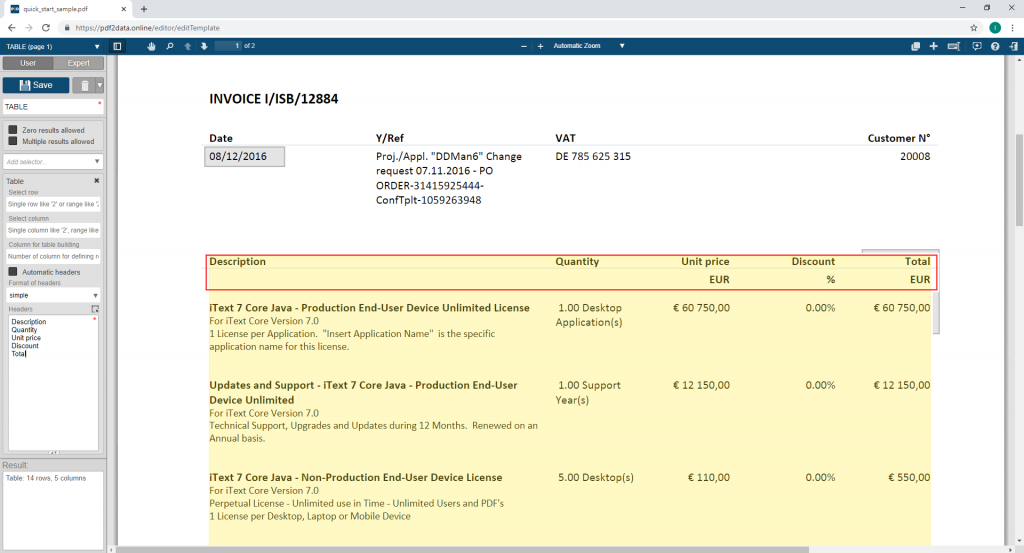
第1步。上传一个PDF文件样本(这将成为识别模板)。
第2步。选择你想提取的文档中的数据,并定义相关的提取规则(选择器),以便正确提取数据。
第3步。上传基于同一模板的任何其他PDF文档,并确认你的数据被正确识别。
第4步。开始在pdf2Data服务器端组件中使用该模板。您可以将它作为一个Java或.NET库集成到您的文档工作流程中,或者作为一个命令行应用程序,使您能够轻松地处理潜在的数百万份文档。

虽然很多库都能帮我们实现PDF的转换,作为编程人员第一要考虑的是产品稳定性和易用性,这作为后续支持和产品学习的一个保证。
而作为项目管理人员需要考虑到成本问题(当然学习成本也是成本),而IText同时满足了以上问题。
“好库”!IText总体而言对开发者友好、功能实现较全、商用没有太多的“增值服务”抬高成本,对专门处理PDF的单一平台而言值得推荐,点击这里了解下国内代理商平台的描述。
当然国产的Spire.Office同样值得推荐,感兴趣的朋友可以点击这里了解一下!